Link Triage Pipeline
Automated knowledge extraction pipeline processing hundreds of links weekly.
The Challenge
My “Read Later” queue was a graveyard of 5,000+ urls. I needed a way to not just archive links, but to extract value from them without human intervention.
The Solution
I built a semi-autonomous pipeline that acts as a dedicated research assistant. It doesn’t just summarize; it triages based on my specific taxonomy.
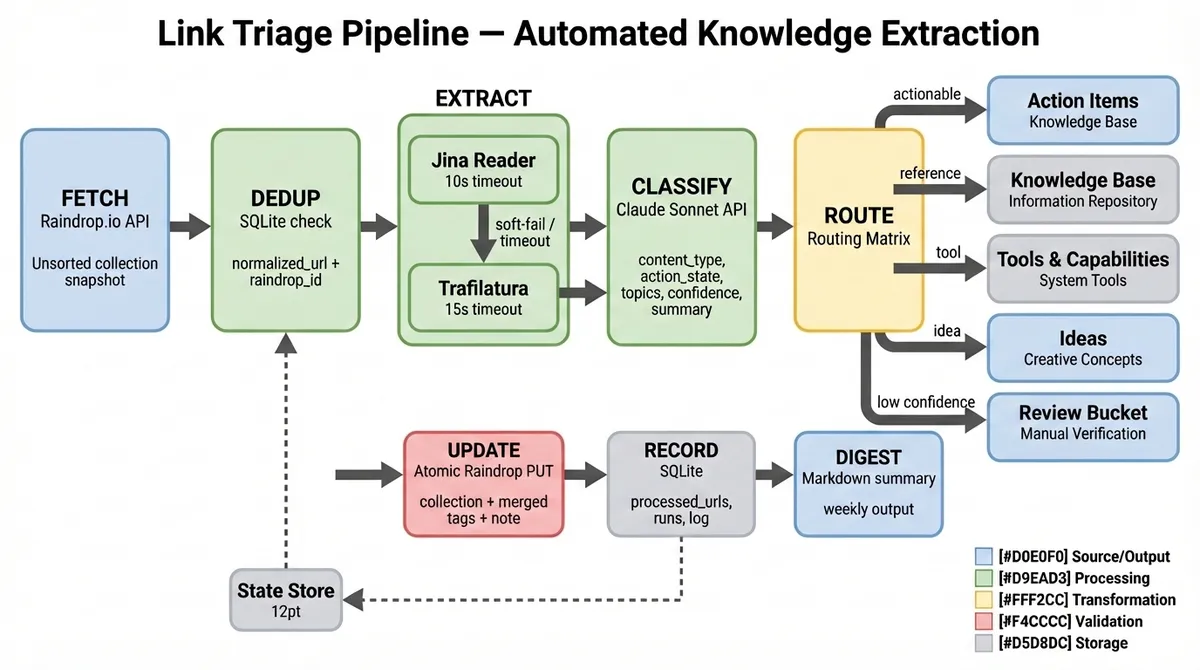
The 5-Phase Pipeline
- Fetch: Pulls new bookmarks from Raindrop.io via API.
- Extract: Uses
JinaandTrafilaturato get clean, readable text (no ads/nav). - Classify: Sends content to Claude 3.5 Sonnet with a specific prompt: “Is this a Tool, a Tutorial, or Strategy? tag it against my personal taxonomy.”
- Route: Updates the Raindrop bookmark with the new tags and an AI-generated note.
- Digest: Generates a weekly Markdown summary of “High Value” reads.
Key Engineering Decision: Semi-Autonomy
Instead of a fully autonomous loop that might burn API credits on junk loops, I implemented a “Human-in-the-Loop” Orchestrator.
The execute-plan CLI runs each phase but pauses for a “quality gate” check. I can run /execute-plan --start-phase 3 to resume work. It balances automation speed with human architectural oversight.
Impact
- Zero Backlog: Inbox processes automatically.
- High Signal: I only read what the AI has pre-qualified as relevant to my current projects.
- Knowledge Graph: My bookmark collection is now a structured, tagged datasets ready for RAG (Retrieval Augmented Generation).