Memory Layer
A local-first, research-validated persistent memory service for agentic workflows — giving agents cross-session recall, contextual continuity, and a structured home for everything they learn.
The Problem
Every agent session starts partially blind. ADF agents can’t learn from past sessions. Cross-project patterns go unnoticed. Personal preferences must be restated. The agent ecosystem had a Knowledge Base (“what we know”) and a Work OS (“what we’re doing”) — but nothing for “what we remember.”
Without persistent contextual memory, isolated agent sessions never become a continuous, learning system. The Memory Layer closes that gap.
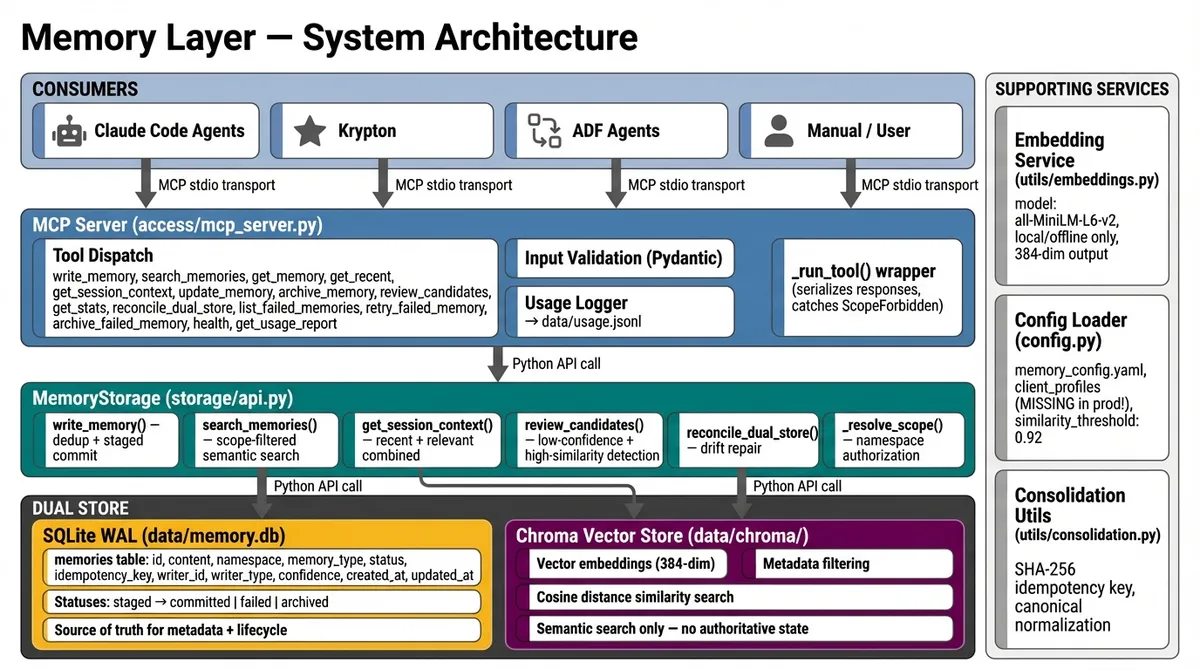
Architecture
The system is a 3-layer MCP server backed by a dual store:
Consumers (Claude Code, Krypton, ADF agents, manual)
│ MCP stdio transport
▼
MCP Server — 15 tools, Pydantic validation
│
▼
MemoryStorage — business logic layer
│ │
▼ ▼
SQLite WAL Chroma
(metadata + (vector embeddings +
lifecycle) semantic search)The storage philosophy: SQLite is the source of truth. Chroma is search-only. Memories float through a staged commit lifecycle: staged → active → archived. Idempotency is enforced via SHA-256 on canonical content — exact duplicates are rejected at the write path.
Embeddings: all-MiniLM-L6-v2, running locally and offline. No cloud dependency, no API cost, 384-dimensional output. Deliberate choice: local-first architecture for a personal memory system means the embeddings model also stays local.
Design Decisions Worth Discussing
Atomic Facts as the Memory Unit
Each memory is one atomic, independently searchable fact. Not a session summary. Not a document. One thing the system learned or observed.
This mirrors what memory research calls “semantic memory” — persistent declarative facts rather than episodic narrative. The tradeoff: richer context requires multiple memories; retrieval relies on good semantic search rather than surrounding context.
Why Dual Store, Not Just SQLite-Vec
SQLite has a sqlite-vec extension for vector search. We chose a separate Chroma process instead. Reason: Chroma’s similarity search is more capable for the semantic search workload, while SQLite handles metadata, lifecycle state, scoping, and audit log — things vectors don’t serve well.
SQLite is in WAL mode, enabling concurrent writes from multiple agents without locks.
Staged Commit + Idempotency
write_memory(content, namespace, writer_id, memory_type, confidence)
→ SHA-256(namespace + canonical(content))
→ INSERT status=staged
→ Promote to active (or detect duplicate)Staged commit means a memory isn’t queryable until it’s been committed. Idempotency means the same memory written twice (common in agent workflows) produces one record, not two.
What the Research Validated — and What It Revealed
Before building, I synthesized six research documents covering production agentic memory architectures. Key findings:
Validated: Local-first SQLite + vector is the right pattern for single-user systems. Atomic facts as the memory unit. Staged commit + idempotency.
Gap surfaced: The 4-Tier Model. Production memory systems use four tiers; we built one:
| Tier | Status |
|---|---|
| Short-term / Working | Lives in context window + status.md — not Memory Layer |
| Episodic | Not implemented — the most significant gap |
| Semantic | ✅ Built — this is the Memory Layer |
| Procedural | Lives in CLAUDE.md / ADF rules — outside Memory Layer |
The episodic tier — a chronological record of what happened and when — is entirely absent. A semantic memory says “the API uses v2 format.” An episodic memory says “on Feb 15, we discovered the API changed from v1 to v2 when the integration test broke.” Both are needed.
Gap surfaced: Semantic-Only Search. Production systems use hybrid search (70% vector + 30% BM25 keyword). Pure vector search fails on exact technical identifiers — function names, error codes, version strings. SQLite already has FTS5 built in. Adding BM25 is low-cost and high-value.
Gap surfaced: No Citation Provenance. Memories are written with no reference to their source. A memory written in February may be factually wrong by June, with no way to detect the drift. The JIT Verification pattern (store a citation at write time, verify at retrieval) makes memory self-healing.
Connection to the Agentic Work System
Memory is Knowledge Ring infrastructure — it serves every layer of the system. ADF agents use it for cross-session recall. Krypton queries it when synthesizing focus recommendations. The capture protocol (what gets written to Memory vs. Knowledge Base) is defined in the AWS architecture.
The routing rule: atomic facts, preferences, decisions, and observations → Memory. Evergreen curated knowledge and research → Knowledge Base. Session state → status.md.